python实现文法左递归的消除方法
(编辑:jimmy 日期: 2026/7/5 浏览:2)
前言
- 继词法分析后,又来到语法分析范畴。完成语法分析需要解决几个子问题,今天就完成文法左递归的消除。
- 没借鉴任何博客,完全自己造轮子。
开始之前
- 文法左递归消除程序的核心是对字符串的处理,输入的产生式作为字符串,对它的拆分、替换与合并操作贯穿始终,处理过程的逻辑和思路稍有错漏便会漏洞百出。
- 采用直接改写法,不理解左递归消除方法很难读懂代码。
要求
- CFG文法判断
- 左递归的类型
- 消除直接左递归和间接左递归
- 界面
源码
import os
import tkinter as tk
import tkinter.messagebox
import tkinter.font as tf
zhuizhong = ""
wenfa = {"非左递归文法"}
xi_ = ""
huo = ""
window = tk.Tk()
window.title('消除左递归')
window.minsize(500,500)
#转换坐标显示形式为元组
def getIndex(text, pos):
return tuple(map(int, str.split(text.index(pos), ".")))
def zhijie(x,y):
if not len(y):
pass
else:
if x == y[0]:
wenfa.discard("非左递归文法")
#处理直接左递归
zuobian = y.split('|')
feizhongjie = []
zhongjie = []
for item in zuobian:
if x in item:
item = item[1:]
textt = str(item) + str(x) + "'"
feizhongjie.append(textt)
else:
text = str(item) + str(x) + "'"
zhongjie.append(text)
if not zhongjie:#处理A -> Ax的情况
zhongjie.append(str(x + "'"))
cheng = str(x) + " -> " + "|".join(zhongjie)
zi = str(x) + "'" + " -> " + "|".join(feizhongjie) + "|"
text_output.insert('insert','直接左递归文法','tag1')
text_output.insert('insert','\n')
text_output.insert('insert',cheng,'tag2')
text_output.insert('insert','\n')
text_output.insert('insert',zi,'tag2')
'''
加上会判断输出非递归产生式,但会导致间接左递归不能删除多余产生式
else:
h ="不变: " + x + " -> " + y
text_output.insert('insert','非左递归文法','tag1')
text_output.insert('insert','\n')
text_output.insert('insert',h,'tag2')
'''
text_output.insert('insert','\n')
def zhijie2(x,y):
if not len(y):
pass
else:
if x == y[0]:
wenfa.discard("非左递归文法")
#处理直接左递归
zuobian = y.split('|')
feizhongjie = []
zhongjie = []
for item in zuobian:
if x in item:
item = item[1:]
textt = str(item) + str(x) + "'"
feizhongjie.append(textt)
else:
text = str(item) + str(x) + "'"
zhongjie.append(text)
cheng = str(x) + " -> " + "|".join(zhongjie)
zi = str(x) + "'" + " -> " + "|".join(feizhongjie) + "|"
text_output.insert('insert',"间接左递归文法",'tag1')
text_output.insert('insert','\n')
text_output.insert('insert',cheng,'tag2')
text_output.insert('insert','\n')
text_output.insert('insert',zi,'tag2')
text_output.insert('insert','\n')
def tihuan(xk,yi,yk):
yi_you = []
yi_wu =[]
yi_he = ""
yi_wuhe = ""
yi_zhong = ""
yi_feizhong = []
if xk in yi:
yk_replace = yk.split('|')
yi_fenjie = yi.split('|')#将含非终结与不含分开
for ba in yi_fenjie:
if xk in ba:
yi_you.append(ba)
else:
yi_wu.append(ba)
yi_he = "|".join(yi_you)
for item in yk_replace:
yi_zhong = yi_he.replace(xk,item)#替换
yi_feizhong.append(yi_zhong)
yi_wuhe = "|".join(yi_wu)#再合并
global zhuizhong
zhuizhong = "|".join(yi_feizhong) + "|" + yi_wuhe
#点击按钮后执行的函数
def changeString():
text_output.delete('1.0','end')
text = text_input.get('1.0','end')
text_list = list(text.split('\n'))#一行一行的拿文法
text_list.pop()
if not text_list[0]:
print(tkinter.messagebox.showerror(title = '出错了!',message='输入不能为空'))
else:
for cfg in text_list:
x,y = cfg.split('->')#将文法左右分开
x = ''.join(x.split())#消除空格
y = ''.join(y.split())
if not (len(x) == 1 and x >= 'A' and x <= 'Z'):
pos = text_input.search(x, '1.0', stopindex="end")
result = tkinter.messagebox.showerror(title = '出错了!',
message='非上下文无关文法!坐标%s'%(getIndex(text_input, pos),))
# 返回值为:ok
print(result)
return 0
else:
zhijie(x,y)
for i in range(len(text_list)):
for k in range(i):
xi,yi = text_list[i].split('->')
xi = ''.join(xi.split())#消除空格
yi = ''.join(yi.split())
xk,yk = text_list[k].split('->')
xk = ''.join(xk.split())#消除空格
yk = ''.join(yk.split())
tihuan(xk,yi,yk)
tihuan(xk,zhuizhong,yk)
global xi_
xi_ = xi
zhijie2(xi_,zhuizhong)
for item in wenfa:
text_output.insert('insert',item,'tag1')
#创建文本输入框和按钮
text_input = tk.Text(window, width=80, height=16)
text_output = tk.Text(window, width=80, height=20)
#简单样式
ft = tf.Font(family='微软雅黑',size=12)
text_output.tag_config("tag1",background="yellow",foreground="red",font=ft)
text_output.tag_config('tag2',font = ft)
#按钮
button = tk.Button(window,text="消除左递归",command=changeString,padx=32,pady=4,bd=4)
text_input.pack()
text_output.pack()
button.pack()
window.mainloop()
是不是很难懂,看看半吊子流程图主要流程

直接左递归

间接左递归合并

运行截图

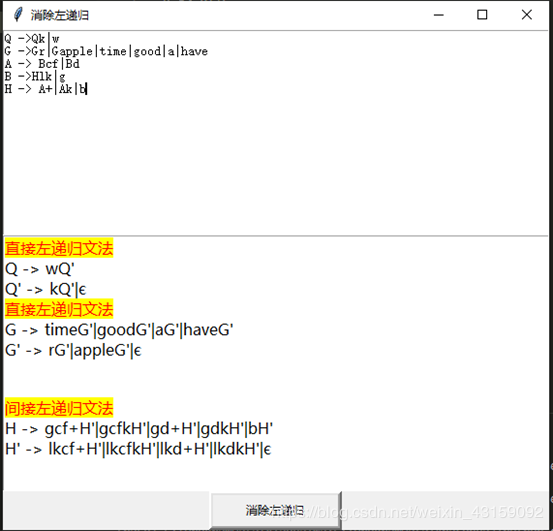
总结
(1)确定方向
做一件事并不难,最难的是没有方向,不知道要做什么;只是感觉时光流逝自己却一点东西都没产出。幸好有具体的题目可供选择,这一次我稍有纠结之后,果断选择文法左递归消除,说实话,我认为这个最简单。
(2)开始实现
首先将消除左递归的方法理解透彻,找到了程序的本质就是对字符串的操作。
完成直接左递归算法非常顺利,我思路严谨步步为营,几乎没有bug,后续测试仅仅加上一些边缘情况的判断,比如空值,让程序面对复杂产生式也游刃有余。
将间接左递归的产生式合并的算法也很顺利,因为我在草稿纸上已经勾勒好了每一步需要得到什么,写代码时,一步一个输出,看是否符合预期,后续测试稍微小补增强健壮性。真正难点在于构思思路,就连最外层两个迭代都考虑了很久。
这两个算法的逻辑和思路是很复杂的,字符串的分分合合,分别存储,使用列表和字符串数据类型不下十个,再加上几个全局变量,我对自己清晰的思路略感自豪。
(3)不足之处
1、我希望能够实现,非左递归文法,左递归和间接左递归的一起输入一起识别一起消除,碰到非左递归文法就输出“非左递归文法”,然后将其不做任何修改输出。如果实现这个,如何让间接左递归不被当做非左递归文法处理呢?我没想到解决方案。
2、我对非终结符的判断采用的是是否包含,没有更进一步判断位置,比如消除 D -> Dh|sD|h,D在s后,这就不能很好的处理。
3、对于间接左递归文法产生式的输入顺序是有要求的,还没能做到随意输入。
(4)遇到的问题
我遇到的问题都是关于整体结构和取舍妥协,比如我最终选择将输入使用两个循环,一个是对一个个产生式进行迭代,消除直接左递归,第二个再从头采用下标嵌套两层循环来合并间接左递归。
在解决不足之处1时,我花了不少时间,用尽了方法,比如全局变量,集合,甚至还将代码备份,进行较大改动,最后还是妥协了。
在写两个核心算法的时候,我每一步拿到什么数据类型,拿到什么内容,都很小心的确认,一步一步推进,没出现“bug找一天”的情况。每到一步需要一个新的变量存储,我就在方法最开始加一个,tihuan()这个方法就有六个变量,现在想来,空间复杂度挺高。
(5)总结
这次的设计完全自主,没有借鉴任何博客,我也知道可能有些我认为很难的东西在大牛面前都不值一提,或许程序整体架构就差之甚远。无论如何,题目要求的东西我做到了,而且花的时间不算长,还是挺有成就感。但是,我绝对不会骄傲,根本没有骄傲的资本。
从画出界面,接收文本输入,取到产生式,判断类型,消除直接左递归,合并间接左递归再到消除间接左递归。有条有理,一步一个脚印,方能万丈高楼平地起。